

I've recently been working on a new database utility that my company are releasing, helped by our intern-turned-employee Tom. One of the areas that I've been focussing on, for the first time in a while, is testing support for international characters and different character encodings. Tom is new to testing of this nature and working with him on this has reminded me of two things: firstly how difficult testing support for international characters can be, and secondly how enjoyable it is.
Tackling the challenge of ensuring data preservation and consistency across different data applications is a tricky job that I've seen trip many people up. In that difficulty comes a great deal of satisfaction when you understand behaviours and identify problems. I thought that, while working in this area, it might be useful to document some of the tips and gotchas that I have encountered.
Don't Trust Characters
The single biggest mistake that I've seen people make working on data verification is to base their deductions on the characters that are presented to them by their application interfaces. I have found the characters that are presented in an application interface to be an extremely unreliable means of checking the data that has been transferred or stored in a data system.
The reason is simple. Data is not stored or transferred as characters. This is done in the form of streams of bytes. The decision on how to present those bytes as characters is typically only made at the point of presenting it to the interface. The thing is, much as the metaphorical tree in the forest, the data won't actually 'appear' unless someone views it, and in order to do that it must be mapped to characters. The decision on how to present a byte or set of bytes as a character will depend on the encoding that the application is using and that can vary between applications and interfaces.
This exposes the tester to the possibility of two fundamental characteristics of character data which, in my opinion, are the most important to understand when working with data and systems of this nature:
1. The same data can appear as different characters when presented using a different encoding.
2. Different data can appear the same when presented using a different encoding.
What really confuses the matter is that the decision on which encoding to use is not made in one place, it will depend on factors internal to the application itself and in its operating environment. These include the data, the operating system, the database settings, the application settings and even the method of connection.
All about encodings
I'm not going to cover character sets and encodings in detail here as it is much too broad a subject. I will present some of the key encodings and their characteristics, but I suggest if working on any data system to read up and gain a solid understanding of character encodings. Character Encodings are a mechanism to map stored information to specific characters. Each encoding discussed here maps a byte or set of bytes to the code points in the encoding, each of which typically then represents a character, punctuation mark or control.
Single byte encodings.
Single byte encodings involve the storing of data in which a single byte is used to represent any individual character or control code. Hence single byte encodings are limited to the range of unique single bytes, at most 256 characters. Most are based around using the 7-bit Ascii encoding to map the byte range 1-127 ( or 0x01 to 0x7F ) to the basic Latin characters, numerics and punctuation required for the English language. Clearly there were many languages based on other accentuation, characters and alphabets and different encodings evolved around the use of 8-bits, or 1 byte, which support different ranges of characters in the 128-255 ( 0x80 to 0xFF ) in an attempt to support these. Many different single byte encodings exist which map this small range of possible single byte 'extended' code points to different characters. Some examples of common ones that I've encountered.
- ISO-8859-1 - common Western Latin
- ISO-8859-15 - European Latin - slight differences from ISO-8859-1 including the Euro symbol
- Windows-1252 - Windows specific Latin encoding
- Cyrillic/ISO-8859-5 - Maps most of the bytes in the 0x80 to 0xFF to letters from the Cyrillic alphabet
- Mac OS Roman - Mac specific Latin mapping
Unicode encodings
Unicode encodings are different from single byte ones in that they are designed to support unique representations of every possible character in every language, and Unicode uniquely defines a specific unique code point for every character. In order to represent this many unique points it is clear that more than one byte per character is required, and different Unicode encodings exist to map multiple bytes to each unique unicode code point.
- UTF-8 This is the unicode encoding most used in Linux and Unix based operating systems. One of the greatest assets of UTF-8 can also prove to be a cause of great confusion when it comes to testing. That is that the first 127 points are single byte, and match exactly to the Ascii single byte encoding. This means that you can convert data encoded in UTF-8 with a single byte encoding and much of the data will appear as you expect. It is only when code points above the 0-127 range are used that the confusion starts as UTF-8 uses 2 or more bytes for all characters outside this range. Many times I've been presented with something like this
- UTF-16 This is the encoding used for Unicode operations on Windows operating systems. Many windows applications will use the term 'Unicode' to refer to UTF-16 which can be confusing if you are working across operating systems. UTF-16 uses at least 2 bytes, sometimes 4, for every code point. Therefore it is incompatible with single byte encodings which, whilst making it sometimes less efficient, at least avoids confusion and ambiguity between UTF-16 data and single byte data.
- UTF-32 I've not had a great deal of experience with UTF-32 - I know that it uses exactly 4-bytes for each code point, there is no variability in the number of bytes used for each code point, but I've not encountered this much in commercial use.
 as an example of corrupt data, when in actual fact it was UTF-8 data being viewed in an application using a single byte encoding. (As a rule of thumb, if when looking at your data you see a lot of "Â" characters - you're viewing multi-byte data using a ISO-8859 encoding).
as an example of corrupt data, when in actual fact it was UTF-8 data being viewed in an application using a single byte encoding. (As a rule of thumb, if when looking at your data you see a lot of "Â" characters - you're viewing multi-byte data using a ISO-8859 encoding).
Given the many different encodings that can be used it is hardly surprising that confusion occurs. Whilst the increasing use of Unicode encodings, in preference to the legacy single byte encodings, is solving many of the problems involved with abiguity in character encodings, anyone testing with legacy data or across multiple systems will need to maintain awareness of both the single-byte and Unicode encodings that are are in play.
As I've mentioned, character encodings can be influenced by a number of factors. The primary one is the locale that is being used by the operating system or session. In Windows this is controlled via the "Control Panel - Region and Language" panel under "Language for non-Unicode programs". This setting controls the system locale which, amongst other things, sets the encoding used to interpret single byte data. Linux uses UTF-8 as its standard encoding and will typically, in my experience, be configured with a UTF-8 locale. As I describe above, this has the advantages of any data containing bytes solely in range of Ascii being consistent with most single byte source encodings, it can be confusing if dealing with single byte data from different locales e.g. data coming from other systems. The locale in Linux is controlled by the LC_* and LANG environment settings - a decent summary of which can be found here.
Lets look at some areas where I've encountered problems.
Don't trust applications
Application interfaces are the first place that we might look to verify whether the data that we expect is present, however these can be the least reliable. Application interfaces are likely to yield the least visibility and control over what you are seeing. The application may be using operating system settings or internal defaults to perform character mapping, and the absence of access to underlying data makes it hard to be sure what is stored.
In client-server or n-tier systems the problem is made worse due to the potential for both client and server side settings to be in play and for data transformations to be occurring in internal layers that you have no visibility of.
As I demonstrated in this post it can be hard to understand what s going on between the various interfaces of a data system. If the characters being presented are not what you expect then you might need to examine the data settings of the application and use application tracing to help understand the situation (of course, here you are beholden to the quality of that tracing).
Another thing that you need to bear in mind when viewing character data in an application is whether the font that is being used by that application is capable of displaying the characters represented by your data. Some fonts are limited to specific ranges of characters, with support for Chinese characters often missing due to the sheer number of characters required. If you are using an application that allows control over fonts then changing to a font that is appropriate for the data that you are viewing may be necessary to view the characters it represents.
When looking to test data systems to check the validity or conservation of data, the application interface can provide useful immediate feedback that something is wrong , however if you want to really see what is stored then getting access to the underlying data is essential.
Don't trust Databases
Accessing a database directly should be a much less ambiguous operation than working through an application interface, however it can still be confusing. I've seen a number of issues raised with our support teams resulting from confusion as to what a customer is seeing.
When accessing databases directly you are still using an application. This may be a GUI based application such as SQL Server Management studio or Toad, or a command line like SQLplus. It is still a client application and it pays to understand how the data is being presented. Inserting character data via a console or GUI interface using SQL is particularly unreliable as the bytes that are stored may differ from those intended based on the database settings and the interface used.
Databases will store data typically as single-byte CHAR/VARCHAR columns, or as unicode/variable-byte NCHAR/NVARCHAR columns. There are two important properties that need to be understood when working with character data in databases.
- The database will use a CHARACTER SET to map the single byte column data. This character set is usually chosen from the same set of single-byte character sets that are used in most operating systems, however as we will see this is not always the case.
- A database will also support a COLLATION which dictates sort order and equivalence when comparing character data - for example whether upper case and lower case letters are considered equivalent when comparing and sorting, and whether accented letters match to non-accented ones or not.
Different databases have different implementations with regard to character sets and collations - Sqlserver , for example, uses the collation of a database, table or column to cover both the character set of data on the server and the SQL collation. Oracle, on the other hand, supports different properties for the character set and collation of a database, table or column.
The effect of character sets on character columns is nicely demonstrated in SQLServer if we run a simple script to populate the bytes from 1 to 255 into columns, each using a different collation.
CREATE TABLE MixedEncodings
(
code TINYINT PRIMARY KEY,
Arabic_CS_AS CHAR(1) COLLATE Arabic_CS_AS NULL,
Cyrillic_General_CS_AS CHAR(1) COLLATE Cyrillic_General_CS_AS NULL,
Latin1_General_CS_AS CHAR(1) COLLATE Latin1_General_CS_AS NULL
Chinese_PRC_CS_AS CHAR(1) COLLATE Chinese_PRC_CS_AS NULL,
Vietnamese_CS_AS CHAR(1) COLLATE Vietnamese_CS_AS NULL
);
INSERT INTO MixedEncodings(code) VALUES (1),(2),(3),(4),(5),(6), ... you get the idea ... (253), (254),(255)
UPDATE MixedEncodings
SET Arabic_CS_AS=CAST(code AS BINARY(1)),
Cyrillic_General_CS_AS=CAST(code AS BINARY(1)),
Latin1_General_CS_AS=CAST(code AS BINARY(1)),
Chinese_PRC_CS_AS=CAST(code AS BINARY(1)),
Vietnamese_CS_AS=CAST(code AS BINARY(1))
We can see that the result of querying this data is that the "code" byte is mapped to different characters at the point of presenting the results of querying the different columns, based on the collation of each column.

Yet, based on a CAST of the data to Binary we can see that the actual bytes stored in the column are the same for each column, it is the collation that is dictating that these bytes be presented as different characters, a neat demonstration of fundamental characteristic number 1 that I highlighted at the start.

This will not always be the case. The same text data, stored in NCHAR or WCHAR columns will have different underlying byte encodings from single byte CHAR data. I've had to deal with confused customers who were comparing HEX output from their source database with my product, not realising that our underlying UTF-8 server encoding resulted in different bytes to represent the same character data as their source single byte encoding, fundamental characteristic number 2. To avoid confusion when creating test data in databases I recommend, as with the example above, explicitly injecting data using binary format rather than attempting to insert characters using SQL string INSERT statements.
As I hinted above, some databases do not use standard character encodings but have their own custom encodings, which can trip up the unwary. Teradata uses different encodings for the data on the server and the client, and the Teradata Latin server encoding is a custom one which does not match any of the ISO or windows single byte latin ones. The byte 0xFF in ISO-8859-1 is the character ÿ, yet that byte loaded into Teradata using the Teradata custom Latin encoding is the Euro symbol. Therefore the resulting characters when a single byte file is loaded into a teradata database will be slightly different from those we might expect from looking at the source file from the operating system terminal.
In fact, while we are on the subject of terminals...
Don't trust Terminals
Working with command line connections can be particularly misleading, as folks often don't realise that these are applications which will have their own encodings to map bytes to characters, which are sometimes independent from the system being connected to. I think the fact that it is a command line leads people to place more trust that they are seeing the data 'as it appears on the server'.
Some terminals will not support unicode by default, and are often limited to specific fonts which, as mentioned, can result in the inability to present certain characters. Here, for example, is a small file containing a mixture of characters from different alphabets stored in a unicode file, viewed via the windows command line.:-

Remote console connections can be particularly bemusing. I've dealt with confused clients who were trying to view multi-byte data using a putty terminal, not realising that this was using a single byte encoding to present characters, when the database server they were connecting to was using a utf-8 encoding. The character set setting for putty is found in the connection properties - when working with Linux I have found that changing this to UTF-8 by default avoids a lot of mistakes.

here are some examples of the same data viewed in different putty sessions with changed encodings - the first with a default Latin encoding and the second with the correct UTF-8 setting:-

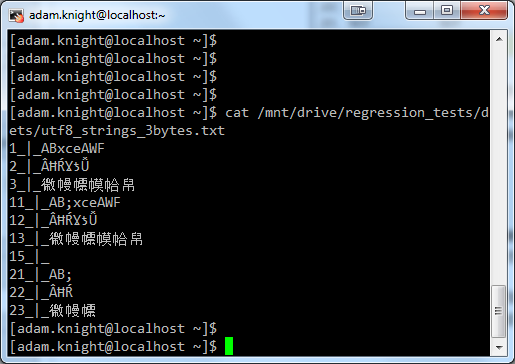
Sometimes it is easier rather than viewing remotely to get the files onto your machine and view them there, or is it.....?
Don't trust files
Even looking at files on a local machine is fraught with peril. Copying files needs to be done in binary transfer mode to avoid changing characters 'helpfully' for your operating system. Then you need to make sure that you view the file using an appropriate tool. Using a text editor brings you back to the problem of applications.
One of the classic mistakes that I've seen people make is to open a unicode file in a text editor, not seen the characters that they expected, so performed a File - Save As and re-encoded the data as presented, i.e. the incorrectly interpreted set of characters, back into Unicode format thus permanently losing the original data. Luckily text editors are getting better at automatically detecting Unicode encodings, however Windows achieves this throuh the use of a "BOM" (Byte order marker) at the start of the file which can be confusing when viewing in other operating systems or as Hex. There are excellent editors such as Notepad++ which allow you to select the encoding that you want to use to view the data, without modifying the file.

There is still need for care here - the "Encode" menu items here do not change the data, only the encoding used to present the data as characters. The lower "Convert" options however will encode whatever characters are currently in the application window into the encoding selected, very much as I've described above. A useful option but one to be used with care.
So What Do I trust
The main thing that you need to be able to trust when working with international data and different encodings is your own understanding. If you are confident in what you are looking at, what are expecting to see and where you can trust the characters that you are seeing, then the battle is almost won. Working out where data is stored, what translations it undergoes and what encoding is being used to map that data to representable characters is critical to make sure that your testing is based on the appropriate target behaviours.
The most reliable way that I've found to verify the content of data is to view using a Hex Editor. The hexdump command on Linux with the -c option is a great way to view character files. On Windows I've found HHD Hex Editor Neo very useful as it allows you to view Hex data alongside different encoding representations of the same bytes, including Unicode ones. Most Hex editors are limited to single byte representations.
In addition to allowing the viewing of the underlying bytes in a data file, many Hex editors also support the comparison of files. The downsides of comparing in hex is that you don't tend to get the nice matching and alignment that comes with textual comparisons. If you can obtain supposedly identical data in a matching encoding and format, including line endings and delimiters, then hex comparison can be a very precise and surgical means of checking for consistency.
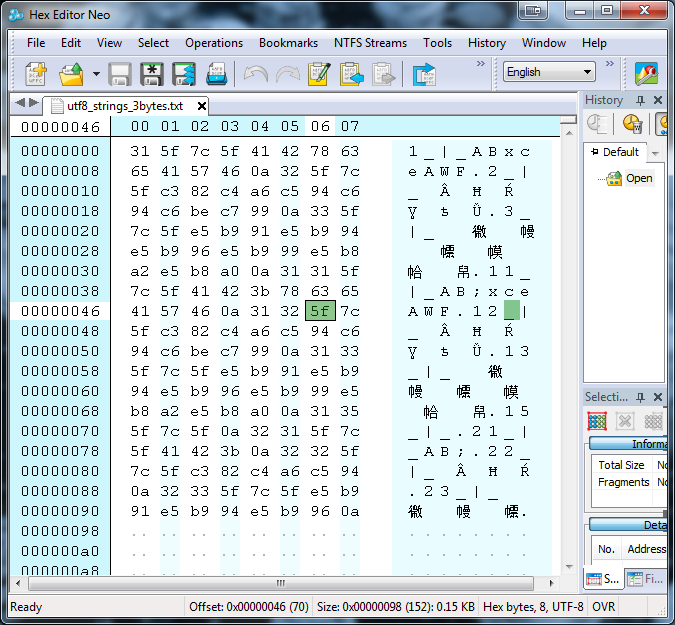
As I mentioned in the 'database' section you can't necessarily rely on a difference in bytes indicating a difference in the character data that is represented. Remember the second of the key principles presented at the start. However if you can obtain data in a consistent format then viewing as hex can remove all manner of confusion as to differences that you are seeing. I also suggest that, where possible, data comparisons will be done programatically based on the byte content of the data rather than relying on visualising the characters. I have a Java program that I use to compare output files from our application with the source data loaded in to validate data conservation within the system.
One trick that I also find particularly helpful for testing character data conservation is to create a unicode copy of any character data that I test with. Then I can use this copy to compare back to on a character basis if the transformations that have occurred to the data within the system make binary comparisons to my source data inappropriate, for example if I've imported single byte data into a UTF-8 based system. To check for character support I keep copies of the entire byte ranges for both single byte and unicode encodings as test source data files, these are incredibly useful to push through a data system or process to check for conservation and consistency.
Working with character data can be hugely confusing field if you aren't sure what you are doing. By understanding the key concept that character representations of data are untrustworthy and inconsistent we have a much better chance of avoiding getting caught out. Developing a familiarity with the concepts of encodings and the various settings that control these provides an invaluable foundation for anyone involved in data testing.
Further Reading
As with all things in computing there are multiple layers of complexity to understanding the impact and complexity of character sets, encodings and locales. I've not found the need to delve to the depths, for example, of how the Linux kernel processes to perform data validation operations myself but there is plenty of information available.
- This site has a good summary of the settings and considerations when working with Unicode in Linux.
- A good introduction to code pages on Microsoft can be found here.
- For more generic cross platform considerations this page provides a good concise history of encodings and the implications of mixing between unicode and non-unicode ones
- this blog post provides a good in depth explanation of character encoding considerations, targetted at programmers.






Post a Comment